ステップ1:データストリーミング基盤の構築 - Amazon Kinesis Data Streams
今回のステップの概要とデータ分析パイプラインとの関連について
このステップでは、リアルタイムデータ分析パイプラインの基礎となるデータストリーミング基盤を構築します。具体的には、Amazon Kinesis Data Streamsを使用して、リアルタイムでデータを収集する仕組みを作成します。
データ分析パイプラインにとって、Amazon Kinesis Data Streamsは「データを流し込むベルトコンベア」のような役割を果たします。工場の生産ラインで、各工程から製品が次々とベルトコンベアに流れてくるように、様々なデータソース(Webサイトのアクセスログ、IoTセンサー、アプリケーションのイベントなど)から発生するデータを、リアルタイムで受け取り、次の処理ステップに送り続ける仕組みです。このベルトコンベアがなければ、データは各所に散らばってしまい、効率的に分析することができません。
このステップで学ぶこと
- Amazon Kinesis Data Streamsの概念と作成方法
- データストリームのシャード設定とスループットの理解
- ストリームの監視とメトリクスの確認方法
- リアルタイムデータ処理の基礎知識
リソースの関わりと構成説明
ステップ1で作成するリソースは、データ分析パイプラインの入り口となるデータストリーミング基盤を構築するものです。それぞれのリソースがデータ分析パイプラインにどのように関わるのか、なぜ必要なのか、メリットとデメリットを説明します。
Amazon Kinesis Data Streamsとデータ分析パイプラインの関わり
Amazon Kinesis Data Streams「data-analysis-stream」は、リアルタイムで発生する大量のデータを一時的に保存し、次の処理ステップに送り出す役割を果たします。
なぜ必要なのか?
データ分析において、リアルタイムで発生するデータ(Webサイトのアクセスログ、IoTセンサーのデータ、ECサイトの購入イベントなど)を効率的に収集・処理する必要があります。しかし、データの発生速度と処理速度には差があり、この差を吸収する仕組みが必要です。例えるなら、工場のベルトコンベアのように、次々と流れてくるデータを受け取り、適切な速度で次の工程(データ保存や分析処理)に送り続ける必要があります。
このリソースがあることで得られるメリット:
- データ損失の防止:データの発生速度が処理速度を上回っても、一時的にデータを保持できるため、データを失うことなく処理できます
- スケーラビリティ:シャード数を増やすことで、秒間数百万レコードの処理が可能になります
- リアルタイム分析の実現:データが発生した瞬間に分析処理を開始できるため、迅速な意思決定が可能になります
- 複数の処理先への配信:同じデータストリームから、複数の処理システム(S3への保存、リアルタイム分析、アラートなど)に同時にデータを配信できます
このリソースがない場合の問題点:
- データ損失のリスク:データの発生速度が処理速度を上回ると、データが失われる可能性があります
- 処理の遅延:データを直接処理システムに送信する場合、処理システムがビジー状態だとデータが処理されず、リアルタイム分析ができません
- スケーリングの困難:データ量が急増した場合、処理システムを手動でスケールアップする必要があり、対応が遅れます
- 単一障害点の発生:処理システムに直接データを送信する場合、そのシステムがダウンするとデータ収集全体が停止します
シャードとデータ分析パイプラインの関わり
シャードは、データストリームの処理能力を決定する単位です。1つのシャードは、1秒あたり1MBの書き込みと1000レコードの書き込み、2MBの読み取りを処理できます。
なぜ必要なのか?
データ量が増加した場合、単一の処理チャネルでは対応できなくなります。シャードにより、データを複数のチャネルに分散して処理できるようになります。例えるなら、ベルトコンベアの幅を広げることで、より多くの製品(データ)を同時に運べるようになるようなものです。
このリソースがあることで得られるメリット:
- 処理能力の向上:シャード数を増やすことで、データ処理能力を線形に向上させることができます
- 負荷分散:データを複数のシャードに分散することで、各シャードの負荷を均等化できます
- 柔軟なスケーリング:データ量に応じてシャード数を動的に調整できるため、コスト効率の良い運用が可能です
このリソースがない場合の問題点:
- 処理能力の限界:単一の処理チャネルでは、データ量が増加した場合に対応できません
- ボトルネックの発生:すべてのデータが1つのチャネルを通るため、処理が遅延します
- スケーリングの困難:データ量が増加した場合、システム全体を再設計する必要があります
データ保持期間とデータ分析パイプラインの関わり
Kinesis Data Streamsは、デフォルトで24時間、最大で365日間データを保持します。この期間中は、データを何度でも読み取ることができます。
なぜ必要なのか?
データの処理に失敗した場合や、後からデータを再分析したい場合に、過去のデータにアクセスできる必要があります。例えるなら、ベルトコンベアの途中に一時保管庫を設けて、過去のデータを後から確認できるようにするようなものです。
このリソースがあることで得られるメリット:
- エラーからの回復:データの処理に失敗した場合でも、保持期間内であれば再処理できます
- 再分析の実現:過去のデータを再読み取りして、新しい分析処理を実行できます
- データの検証:処理結果を検証するために、元のデータを確認できます
このリソースがない場合の問題点:
- データ損失のリスク:処理に失敗した場合、データが失われ、再処理ができません
- 再分析の困難:過去のデータにアクセスできないため、新しい分析要件に対応できません
- デバッグの困難:処理結果に問題があった場合、元のデータを確認できないため、原因の特定が困難です
実際の手順
実際の手順では、たくさんの設定値を入力することになります。 本文中に設定値が指定されていない場合は、デフォルト値のまま作業を進めてください。
1. Kinesis Data Streamsの作成
Amazon Kinesis Data Streamsは、リアルタイムで大量のデータを収集・保存・処理するためのマネージドサービスです。これにより、データ分析パイプラインの入り口として、様々なデータソースから流れてくるデータを効率的に受け取ることができます。
1-1. Kinesisコンソールへのアクセス
- AWSマネジメントコンソールにログインします
- 検索バーに「Kinesis」と入力し、Amazon Kinesisを選択します
- ”今すぐ始める”欄の「Kinesis Data streams」を選択します
1-2. データストリームの作成
- 「データストリームを作成」ボタンをクリックします
- データストリーム名に「data-analysis-stream」と入力します
- 容量モードで「オンデマンド」を選択します
【解説】On-demandモードとProvisionedモードの違い
On-demandモードは、データ量に応じて自動的にスケーリングされるモードです。データ量が少ない時はコストを抑え、急激にデータ量が増加した時も自動的に対応できます。これは、工場のベルトコンベアが、製品の量に応じて自動的に速度を調整するようなものです。
Provisionedモードは、事前にシャード数を指定して固定の処理能力を確保するモードです。データ量が予測可能で、常に一定以上の処理能力が必要な場合に適しています。これは、工場のベルトコンベアの速度を固定して、常に一定の処理能力を確保するようなものです。
学習用途やデータ量が変動する場合は、On-demandモードがおすすめです。コスト効率が良く、管理も簡単です。
- 「データストリームの作成」ボタンをクリックします
- ストリームのステータスが「作成中」から「アクティブ」に変わるまで待ちます(通常、数秒から1分程度かかります)
【解説】ストリームのステータス
ストリームのステータスは、ストリームの現在の状態を示します。「作成中」はストリームが作成中であることを示し、「アクティブ」はストリームが使用可能であることを示します。ストリームが「アクティブ」になるまでは、データの送信や読み取りを行うことができません。
ストリームの作成には通常、数秒から1分程度かかります。大量のシャードを指定した場合や、システムに負荷がかかっている場合は、もう少し時間がかかる場合があります。
1-3. ストリームの詳細確認
- 作成したストリーム「data-analysis-stream」の以下の情報を確認します
- データストリーム名: data-analysis-stream
- ステータス: アクティブ
- 容量モード: オンデマンド
- データ保持期間: 1日(デフォルト)
【解説】データ保持期間(Data retention period)
データ保持期間は、ストリームに送信されたデータを保持する期間です。デフォルトでは24時間ですが、最大365日間まで延長できます。この期間中は、データを何度でも読み取ることができます。
データ保持期間を長くすると、データの再処理や過去のデータの分析が可能になりますが、ストレージコストが増加します。一方、データ保持期間を短くすると、コストは削減できますが、データの再処理ができなくなります。
学習用途では、デフォルトの24時間で十分です。本番環境では、データの再処理が必要な期間に応じて設定を調整します。
2. データ送信のテスト(オプション)
実際にデータを送信して、ストリームが正常に動作することを確認します。このステップは、AWS CLIまたはPythonスクリプトを使用して実行できます。
2-1. AWS認証情報の設定
AWS CLIを使用してKinesis Data Streamsにデータを送信するには、まずAWS認証情報を設定する必要があります。
- AWS CLIがインストールされていることを確認します
aws --version- AWS IAM Identity Centerにアクセスし、認証情報を取得します
AWSアクセスポータル(AWS access portal)にアクセスし、使用するアカウントとロールを選択します。
- 「Access keys」をクリックして、認証情報の取得方法を表示します
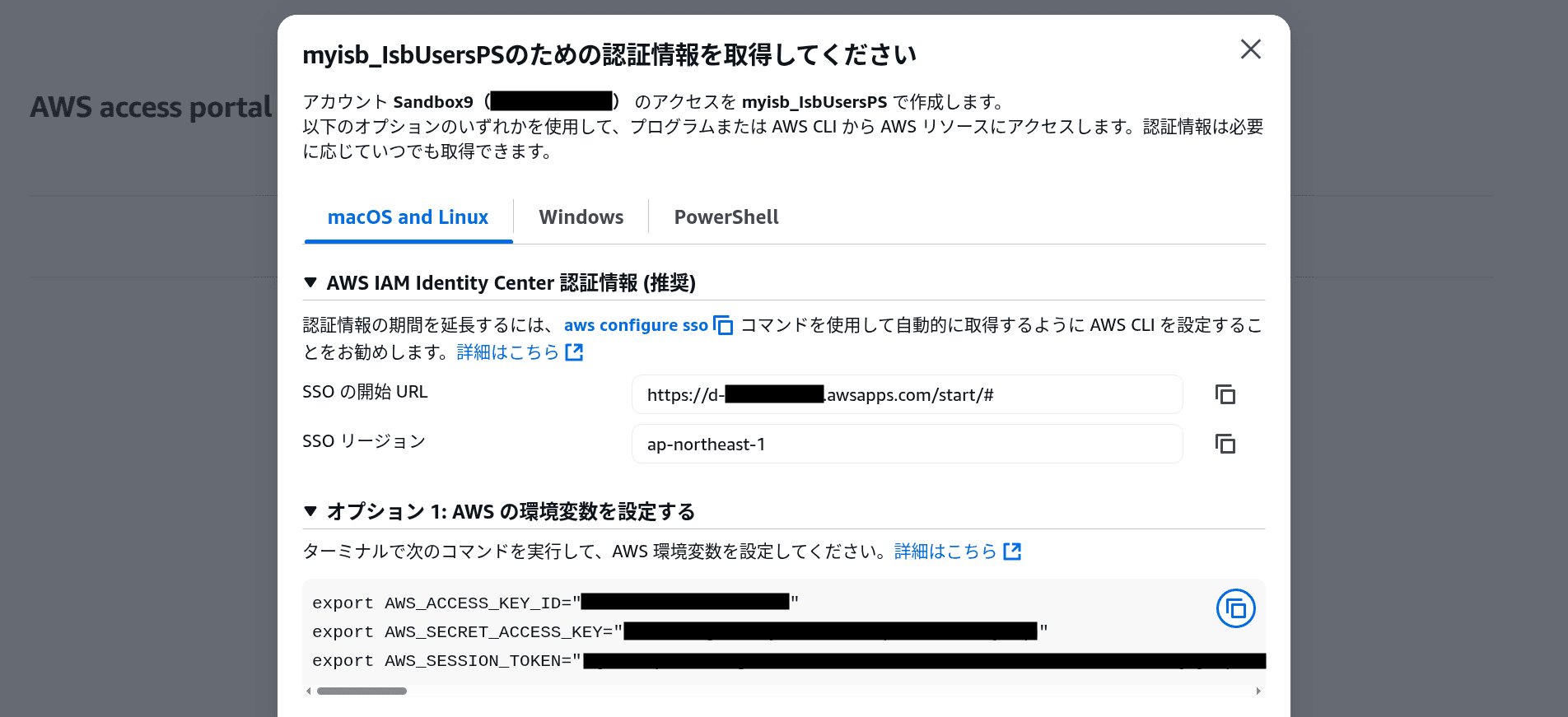
- 「Option 1: Set AWS environment variables」セクションに表示されている環境変数を、ターミナルで設定します
export AWS_ACCESS_KEY_ID="your-access-key-id"
export AWS_SECRET_ACCESS_KEY="your-secret-access-key"
export AWS_SESSION_TOKEN="your-session-token"- 認証情報が正しく設定されているかを AWS STS で確認します
aws sts get-caller-identity以下のような出力が表示されればOKです。
{
"UserId": "XXXXXXXXXXXXXXXXX",
"Account": "123456789012",
"Arn": "arn:aws:sts::123456789012:assumed-role/YourRole/YourSession"
}重要: 上記のコマンドは例です。実際には、AWSアクセスポータルに表示されている具体的な値をコピー&ペーストして実行してください。セッショントークンは一定時間で失効するため、有効期限が切れた場合は再度取得する必要があります。
【解説】環境変数による一時的な認証情報の管理
AWS認証情報は、AWSリソースを操作するための「鍵」です。この鍵を使って、Kinesis Data Streamsへのデータ送信、S3へのファイルアップロード、EC2インスタンスの作成など、あらゆるAWS操作が可能になります。そのため、認証情報の管理は非常に重要です。
AWS IAM Identity Centerを使用した認証方法では、一時的なセッショントークンが発行されます。この方法には以下のメリットがあります:
- セキュリティの向上: セッショントークンは一定時間で自動的に失効するため、永続的なアクセスキーよりも安全です
- 権限の明確化: ロールベースでアクセス権限が管理されるため、必要最小限の権限のみを付与できます
- 監査の容易さ: どのユーザーがどのロールでアクセスしたかが明確に記録されます
環境変数に設定した認証情報は、ターミナルセッションが終了すると消失します。そのため、ターミナルを開き直した場合や、セッショントークンの有効期限が切れた場合は、再度AWSアクセスポータルから認証情報を取得して設定する必要があります。
本カリキュラムでは、学習目的でこの方法を使用しますが、実務では以下の方法も推奨されます:
- AWS CLIのSSOプロファイル:
aws configure ssoコマンドでSSOプロファイルを設定し、自動的にトークンを更新する方法 - IAM Roleの利用: EC2やLambdaなどのAWSリソースには、直接IAM Roleをアタッチして認証情報をコードに埋め込まない方法
- CI/CD環境: GitHub ActionsのOIDCプロバイダーを使用してアクセスキー不要で認証する方法
絶対にGitリポジトリに認証情報をコミットしないでください。.gitignore に .env や credentials ファイルを追加することで、誤ってコミットすることを防げます。
2-2. AWS CLIを使用したデータ送信テスト
AWS CLIがインストールされている場合、以下のコマンドでデータを送信できます:
aws kinesis put-record \
--stream-name data-analysis-stream \
--partition-key "test-partition" \
--data "Hello, Kinesis!" \
--region us-east-1以下のような出力が表示されればOKです。
{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49612345678901234567890123456789012345678901234567890123"
}【解説】パーティションキー(Partition key)
パーティションキーは、データをどのシャードに送るかを決定するキーです。同じパーティションキーを持つデータは、同じシャードに送られます。これにより、データの順序性を保証することができます。
例えば、ユーザーIDをパーティションキーにすると、同じユーザーのデータは常に同じシャードに送られ、データの順序が保証されます。一方、ランダムな値をパーティションキーにすると、データは複数のシャードに分散され、処理の並列性が向上します。
学習用途では、任意の文字列をパーティションキーとして使用できます。本番環境では、データの特性に応じて適切なパーティションキーを選択することが重要です。
このステップで何をしたのか
このステップでは、リアルタイムデータ分析パイプラインの基礎となるデータストリーミング基盤を構築しました。具体的には、Amazon Kinesis Data Streamsを使用して、リアルタイムでデータを収集・保存するストリームを作成しました。
データ分析パイプラインでどのような影響があるのか
この構成により、データ分析パイプラインはリアルタイムでデータを収集できるようになりました。様々なデータソースから発生するデータを、失うことなく効率的に受け取り、次の処理ステップ(データ保存や分析処理)に送り続けることができます。これは、工場のベルトコンベアが各工程から製品を受け取り、次の工程に送り続けるようなものです。また、データ保持期間中は、データを何度でも読み取ることができるため、処理に失敗した場合でも再処理が可能です。
技術比較まとめ表
| 技術領域 | AWS | オンプレミス |
|---|---|---|
| データストリーミング | Amazon Kinesis Data Streams マネージドサービス、自動スケーリング、高可用性 | Apache Kafka 自前でサーバー構築・運用、クラスター管理が必要 |
| スケーラビリティ | オンデマンドモードで自動スケーリング シャード数に応じた処理能力 | 手動でパーティション数を調整 クラスターの追加・削除が必要 |
| データ保持 | 24時間〜365日間の設定可能な保持期間 マネージドストレージ | 設定した期間分のディスク容量が必要 ストレージ管理が必要 |
学習において重要な技術的違い
1. マネージドサービスとセルフマネージドの違い
- AWS:サーバーの構築・運用・監視が不要。AWSが自動的に管理
- オンプレミス:サーバーの構築・運用・監視を自前で行う必要がある
2. スケーラビリティの実現方法
- AWS:オンデマンドモードで自動的にスケーリング。データ量に応じて処理能力が自動調整
- オンプレミス:手動でパーティション数を調整し、クラスターを追加・削除する必要がある
3. コスト構造
- AWS:使用量に応じた従量課金。データ量が少ない時はコストを抑えられる
- オンプレミス:サーバーやストレージの固定コストが発生。データ量が少なくてもコストがかかる
4. 可用性と信頼性
- AWS:AWSが管理する高可用性インフラ。自動的な障害復旧
- オンプレミス:自前で高可用性を実現する必要がある。障害時の対応も自前で行う
実践チェック:画面キャプチャで証明しよう
下記のチェック項目について、実際にAWSマネジメントコンソールで設定ができていることを確認し、各項目ごとに該当画面のスクリーンショットを撮影して提出してください。
- Kinesis Data Streams「data-analysis-stream」が作成され、ステータスが「Active」になっている
- ストリームの詳細画面で、Capacity modeが「On-demand」になっている
- ストリームの詳細画面で、Data retention periodが「24 hours」になっている
- (オプション)AWS CLIまたはPythonスクリプトでデータ送信テストが成功している
提出方法: 各項目ごとにスクリーンショットを撮影し、まとめて提出してください。 ファイル名やコメントで「どの項目か」が分かるようにしてください。
構成図による理解度チェック
このステップで作成したリソースを、データ分析パイプラインの構成図に追加しましょう。
なぜ構成図を更新するのか?
構成図を更新することで、データ分析パイプラインの全体像を視覚的に理解できるようになります。また、各リソースの関係性やデータの流れを明確にすることで、システムの動作を深く理解することができます。
- データの流れの理解: データがどこから来て、どこに向かうのかを視覚的に把握できる
- リソース間の関係性: 各リソースがどのように連携しているかを理解できる
- システム全体の把握: パイプライン全体の構造を一目で理解できる
構成図の書き方
以下のリソースを構成図に追加してみましょう。
- Kinesis Data Streams: 図の左側(データソース側)に配置。データが流れ込む入り口として表現
- データの流れ: データソースからKinesis Data Streamsへの矢印を描く
💡 ヒント: 構成図では、データの流れを左から右に向かって描くと理解しやすくなります。また、各リソースの役割を短い説明文で補足すると、より分かりやすくなります。
理解度チェック:なぜ?を考えてみよう
AWSの各リソースや設計には、必ず”理由”や”目的”があります。 下記の「なぜ?」という問いに自分なりの言葉で答えてみましょう。 仕組みや設計意図を自分で説明できることが、真の理解につながります。 ぜひ、単なる暗記ではなく「なぜそうなっているのか?」を意識して考えてみてください。
Q. なぜKinesis Data Streamsでは、データを直接S3に保存せず、一度ストリームに保存するのでしょうか?ストリームを経由することのメリットは何ですか?
Q. なぜパーティションキーが必要なのでしょうか?パーティションキーを適切に選択することで、どのような効果が得られますか?
Q. なぜOn-demandモードとProvisionedモードが存在するのでしょうか?それぞれのモードは、どのような用途に適していますか?
今回のステップで利用したAWSサービス名一覧
- Amazon Kinesis Data Streams:リアルタイムデータストリーミングサービス