ステップ4:オートスケーリングによる動的なキャパシティ管理
今回のステップの概要とECサイトとの関連について
このステップでは、前回構築したFargateサービスに対してオートスケーリング機能を設定し、負荷に応じて自動的にタスク数を調整する仕組みを構築します。具体的には、ターゲット追跡スケーリングポリシーの設定、CloudWatchアラームの自動作成、そして実際の負荷テストによるスケーリング動作の検証を行います。
ECサイトにとって、オートスケーリングは「需要に応じた店舗スタッフの自動調整システム」のような役割を果たします。セール期間やイベント時の急激なアクセス増加に対して、自動的にサーバー(店舗スタッフ)を増員し、通常時には適切な人数に戻すことで、コスト効率と顧客満足度の両方を最適化できます。
このステップで学ぶこと
- Auto ScalingによるECSサービスの動的スケーリング
- CloudWatchメトリクスを使用したターゲット追跡スケーリング
- 負荷テストによるスケーリング動作の検証
- スケーリングポリシーの設計と最適化
リソースの関わりと構成説明
ステップ4で作成するリソースは、ECサイトの動的なキャパシティ管理を実現するものです。それぞれのリソースがECサイトにどのように関わるのかを説明します。
Auto Scalingと需要対応の関わり
Auto Scaling「自動スケーリング機能」は、ECサイトの「需要予測・人員調整システム」のような役割を果たします。リアルタイムのトラフィック状況を監視し、設定した閾値に基づいて自動的にコンテナ数を増減させることで、常に最適なサービス品質を維持します。これにより、突発的なアクセス増加にも対応できます。
CloudWatchメトリクスと監視の関わり
CloudWatchメトリクス「性能監視システム」は、ECサイトの「店舗運営状況モニター」のような役割を果たします。ALBのリクエスト数、CPU使用率、メモリ使用率などの重要な指標を継続的に監視し、スケーリング判断の根拠となるデータを提供します。これにより、データ駆動型の運営判断が可能になります。
スケーリングポリシーと運営戦略の関わり
スケーリングポリシー「運営戦略設定」は、ECサイトの「営業戦略マニュアル」のような役割を果たします。どの指標をどの閾値で監視し、どのようなタイミングでスケールアウト・スケールインを行うかを定義します。これにより、コストと性能のバランスを自動的に最適化できます。
実際の手順
実際の手順では、たくさんの設定値を入力することになります。 本文中に設定値が指定されていない場合は、デフォルト値のまま作業を進めてください。
1. オートスケーリングの設定
最後にタスクのオートスケーリングを設定する方法を見ていきます。
【AWSでの役割】
Amazon ECSサービスオートスケーリングは、ターゲット追跡スケーリングポリシーを使用して、指定したメトリクスがターゲット値に近づくように、サービス内で実行されるタスクの数を自動的に増減します。利用可能なメトリクスには、平均CPU使用率、平均メモリ使用率、ターゲットあたりのALBリクエスト数などがあり、これらの指標に基づいて最適なキャパシティを維持できます。
【オンプレミスでの対応】
オンプレミス環境では「Kubernetes Horizontal Pod Autoscaler」や「カスタムスケーリングスクリプト」が対応します。これらの環境では、メトリクス収集システムの構築、スケーリング判断ロジックの実装、リソースプールの管理をすべて自社で行う必要があります。
1-1. オートスケーリングを設定する
-
サイドバーの「タスク定義」「ecs-handson-task」を選択し、「デプロイ」「サービスを更新」をクリックします。
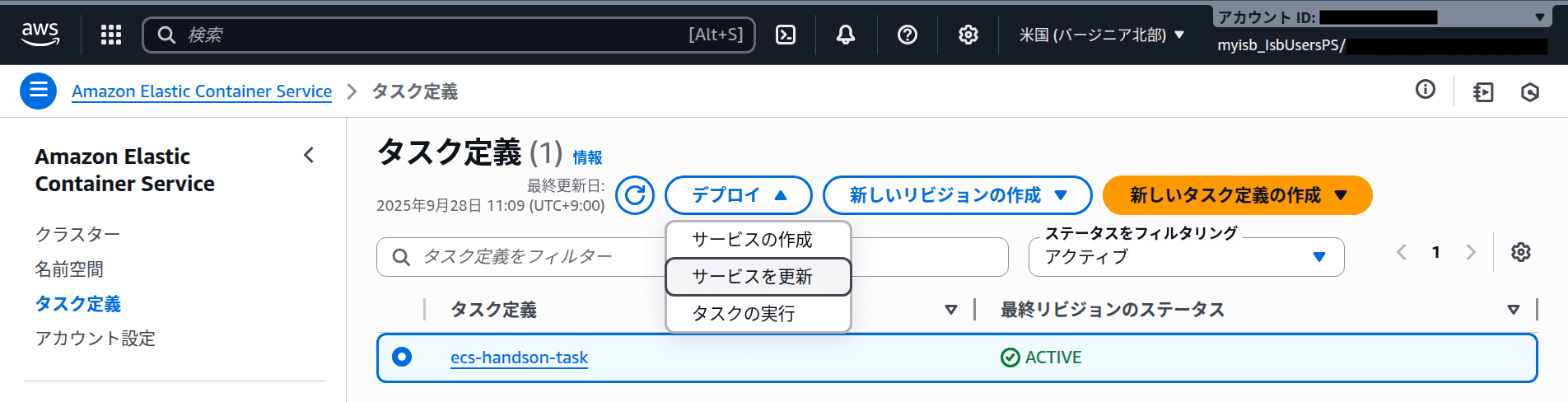
-
ページ後半にある「サービスの自動スケーリング - オプション」を展開しオートスケーリングの設定を入力します。
| 項目 | 設定値 |
|---|---|
| サービスの自動スケーリングを使用 | ON |
| タスクの最小数 / 最大数 | 1 / 10 |
| スケーリングポリシータイプ | ターゲットの追跡 |
| ポリシー名 | ecs-handson-policy |
| ECS サービスメトリクス | ALBRequestCountPerTarget |
| ターゲット値 | 1000 |
| スケールアウトクールダウン期間 | 10 |
| スケールインクールダウン期間 | 300 |
【解説】ターゲット追跡スケーリングの仕組み
ターゲット追跡スケーリングでは、メトリクスがターゲット値に近づくように自動でタスク数を増減します。この設定では、ターゲットあたりの1分間のALBの平均リクエスト数が1000に近づくようにスケーリングポリシーを設定しています。ここでは、早く結果を確認するために、わざと低い値を設定しています。実際の本番環境では、アプリケーションの性能特性とビジネス要件に基づいて適切な閾値を設定することが重要です。スケールアウトクールダウン期間は新しいタスクが安定するまでの待機時間、スケールインクールダウン期間は不要なタスクを削除するまでの待機時間を制御します。
- 以上を設定したら、他の項目はそのままに「更新」をクリックします。
2. オートスケーリングの検証
それでは、実際にリクエストを発生させて、オートスケーリングを体験してみましょう。
【負荷テストツールについて】
負荷テストには様々なツールが利用できます。Macの場合はbrew install hey、Windowsの場合はGitHubリリースページ からheyツールをダウンロードしてインストールすることもできます。ここでは、より汎用的なcurlコマンドを使用した方法も紹介します。
2-1. 負荷テストの実行
- ローカル環境で以下のコマンドを実行し、ALBに対して負荷テストを行います。
# ALBのDNS名を取得
FARGATE_ALB_NAME=ecs-fargate-alb
FARGATE_ALB_DNS=$(aws elbv2 describe-load-balancers --region us-east-1 --name ${FARGATE_ALB_NAME} --query "LoadBalancers[].DNSName" --output text)
# heyツールを使用した負荷テスト(heyがインストールされている場合)
hey -c 10 -z 10m http://${FARGATE_ALB_DNS}
# または、curlを使用した簡易負荷テスト
for i in {1..1000}; do
curl -s http://${FARGATE_ALB_DNS} > /dev/null &
if (( i % 10 == 0 )); then
wait
echo "Sent $i requests"
fi
done2-2. スケーリング動作の確認
-
マネジメントコンソールに戻り、ALBの「モニタリング」タブを開きます。しばらくするとリクエスト数が増加し始めていることが分かります。
-
ECSコンソールでサービス詳細画面の「タスク」タブを開くとタスク数が増加していることを確認できます。
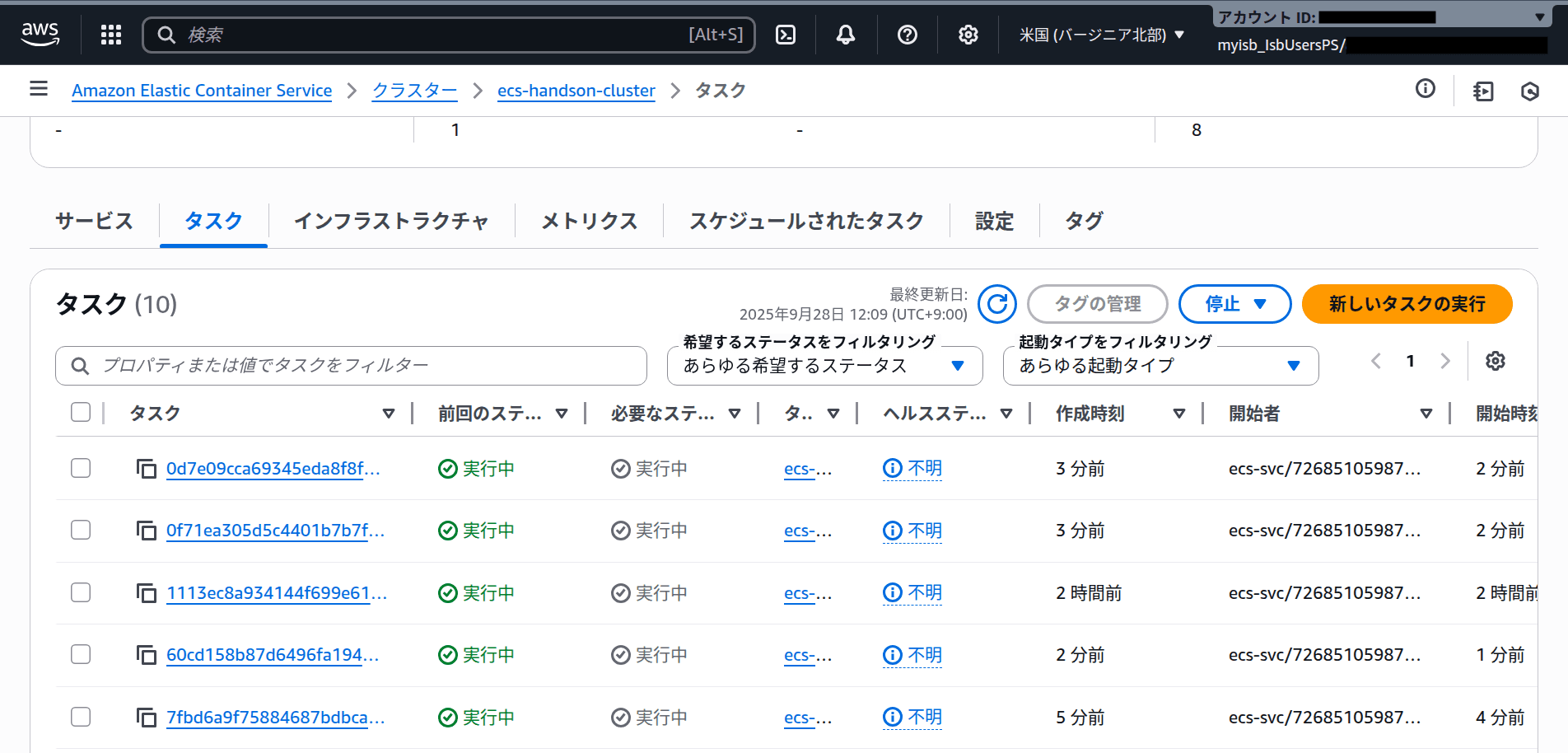
-
「サービスの自動スケーリング」タブを開き「スケーリングアクティビティ」を確認するとdesired countが10まで増加していることが確認できます。
2-3. CloudWatchアラームの確認
-
「設定とネットワーク」タブ内の「Auto Scaling」セクションにあるポリシーの「アラーム」の値をクリックすると、オートスケーリングのために自動作成されたCloudWatch アラームへのリンクが 2 つ表示されます。
-
AlarmHigh という文字列が含まれたアラーム (スケールアウト用のアラーム) を確認すると、3 分間連続して指定した閾値を超えた場合に、スケーリングアクションが呼び出されるように設定されていることを確認できます。
-
同様に、CloudWatch コンソールの「アラーム」では、スケールアウト用のアラームだけでなく、スケールイン用のアラームが作成されていることも確認できます。
【解説】CloudWatchアラームによる自動監視
CloudWatchアラームは、15分間連続して閾値を下回った場合にスケールインアクションが呼び出されるように設定されています。もちろん、この条件を変更することも可能です。検索バーに “service” と入力することで、ECS サービスに関するアラームをフィルタリングできます。このように、オートスケーリングは単純にタスクを増減するだけでなく、CloudWatchとの密接な連携により、包括的な監視とアラート機能を提供します。
お疲れ様でした!このセクションでは、Fargateを使用してコンテナアプリケーションをデプロイし、負荷に応じて自動でスケールさせることができました。
このステップで何をしたのか
このステップでは、Amazon ECSサービスに対してオートスケーリング機能を実装し、動的なキャパシティ管理を実現しました。具体的には、ターゲット追跡スケーリングポリシーを設定してALBリクエスト数に基づく自動スケーリングを構築し、CloudWatchアラームによる監視体制を整備しました。また、実際の負荷テストを通じてスケーリング動作を検証し、システムの自動回復力を確認しました。
ECサイトでどのような影響があるのか
この構成により、ECサイトは需要の変動に自動的に対応できる真に弾力性のあるシステムになりました。セール期間やキャンペーン時の急激なアクセス増加に対して自動的にキャパシティを拡張し、通常時には最小限のリソースで運用することで、コスト効率と顧客体験の両方を最適化できます。これは、繁忙期に応じて自動的にスタッフを増員し、閑散期には適正人数に調整する高度な店舗運営システムに相当します。
技術比較まとめ表
| 技術領域 | AWS | オンプレミス |
|---|---|---|
| オートスケーリング | ECSサービスオートスケーリング ターゲット追跡による自動調整 | Kubernetes HPA 手動でのメトリクス設定とスケーリング |
| 監視・アラート | CloudWatchアラーム 自動作成される包括的な監視 | Prometheus/Grafana 監視システムの独自構築・設定 |
| 負荷テスト | ALBとの統合 リアルタイムメトリクス収集 | 独立した負荷テストツール メトリクス収集の個別実装 |
| キャパシティ管理 | Fargate サーバーレスでの無制限スケーリング | 物理リソース制約 事前のキャパシティプランニングが必要 |
学習において重要な技術的違い
1. スケーリングの自動化レベル
- AWS: ターゲット追跡スケーリングにより、指定したメトリクス値を維持するよう完全自動化されたスケーリングが実現されます。
- オンプレミス: Kubernetes HPAでも基本的な自動スケーリングは可能ですが、メトリクス収集システムやスケーリング判断ロジックの詳細設定が必要です。
2. 監視とアラートの統合性
- AWS: CloudWatchアラームが自動作成され、スケーリングイベントと監視が完全に統合されます。
- オンプレミス: PrometheusやGrafanaなどの監視ツールを個別に設定し、アラートルールも独自に実装する必要があります。
3. リソースの弾力性
- AWS: Fargateにより、理論上無制限のスケーリングが可能で、物理的な制約がありません。
- オンプレミス: 物理サーバーやネットワーク帯域の制約により、スケーリングの上限が事前に決まってしまいます。
4. コスト最適化の自動化
- AWS: 使用したリソース分のみの課金により、自動的にコスト最適化が実現されます。
- オンプレミス: ピーク時に合わせたキャパシティ設計により、平常時のリソース利用効率が低下する傾向があります。
【Fargateのコスト特性と考慮事項】
AWS Fargateは、使用したCPUとメモリリソースに対して秒単位で課金される従量課金モデルを採用しています。これにより、実際の使用量に応じたコスト効率の良い運用が可能になります。ただし、常時稼働するワークロードや高使用率のアプリケーションの場合、EC2インスタンスと比較してコストが割高になる場合があります。また、GPUを必要とするワークロードやカスタムLinux設定が必要なアプリケーションでは、Fargateの制約により実行できない場合があります。詳細なコスト比較や制約事項については、Fargateの料金 およびFargateとEC2のコスト最適化 をご参照ください。
実践チェック:画面キャプチャで証明しよう
下記のチェック項目について、実際にAWSマネジメントコンソールで設定ができていることを確認し、各項目ごとに該当画面のスクリーンショットを撮影して提出してください。
-
Fargateサービスのオートスケーリング設定確認
-
ターゲット追跡スケーリングポリシーの設定確認
-
負荷テスト実行中のALBモニタリング画面
-
タスク数の増加確認(スケールアウト動作)
-
CloudWatchアラームの自動作成確認
-
スケーリングアクティビティの履歴確認
提出方法: 各項目ごとにスクリーンショットを撮影し、まとめて提出してください。 ファイル名やコメントで「どの項目か」が分かるようにしてください。
構成図による理解度チェック
ステップ3のFargateサービス構成図に、このステップで作成したオートスケーリング機能を追記して、完全な動的スケーリングシステムの構成を完成させましょう。
なぜ構成図を更新するのか?
静的なコンテナ実行環境から動的にスケールする環境への進化により、システムの複雑さと柔軟性が大幅に向上しました。この変化を視覚的に理解することで、負荷変動に対するシステムの自動対応メカニズムを明確に把握できます。特に、監視・判断・実行の自動化サイクルを図で表現することが重要です。
- 監視フロー: CloudWatchメトリクス収集 → アラーム判定 → スケーリングアクションの流れ
- スケーリングメカニズム: ターゲット追跡による動的なタスク数調整の仕組み
- 負荷分散の動的調整: ALBによる増減するタスクへの自動トラフィック分散
構成図の書き方
ステップ3で作成したFargateサービス構成図をベースに、以下の要素を追記してみましょう。
- CloudWatchメトリクス: ALBからのメトリクス収集を表現
- スケーリングポリシー: ターゲット追跡の判断ロジック
- 動的タスク: 1〜10個まで変動するFargateタスク群
- CloudWatchアラーム: スケールアウト・スケールインアラーム
- 負荷テスト: ローカル環境からの負荷生成
💡 ヒント: タスクを可変個数で描き、CloudWatchを監視の目のマークで表現。スケーリングポリシーを制御装置として中央に配置しましょう。
理解度チェック:なぜ?を考えてみよう
AWSの各リソースや設計には、必ず”理由”や”目的”があります。 下記の「なぜ?」という問いに自分なりの言葉で答えてみましょう。 仕組みや設計意図を自分で説明できることが、真の理解につながります。 ぜひ、単なる暗記ではなく「なぜそうなっているのか?」を意識して考えてみてください。
Q. なぜオートスケーリングでターゲット追跡スケーリングを使用するのか?
Q. なぜスケールアウトとスケールインで異なるクールダウン期間を設定するのか?
Q. なぜCloudWatchアラームが自動作成されるのか?
Q. なぜALBRequestCountPerTargetをスケーリング指標として使用するのか?
今回のステップで利用したAWSサービス名一覧
- Auto Scaling:自動スケーリングサービス
- CloudWatch:監視・メトリクス収集サービス
- CloudWatchアラーム:自動アラート機能
- ターゲット追跡スケーリング:メトリクス基準の自動スケーリング